
Engineering Skills in Data Science
some of these are not optional anymore for a Data Scientist

In the ever-evolving field of data science, possessing strong engineering skills has become increasingly essential. While statistical knowledge and machine learning expertise are fundamental, the ability to implement, scale, and maintain the data science solutions in the production environment will set the exceptional data scientists apart. These skills enable data scientists to bridge the gap between theoretical models and practical applications, ensuring that insights can be effectively translated into actionable outcomes.
From writing clean, maintainable code and managing version control with Git to leveraging cloud infrastructure and orchestrating containerized applications, engineering competencies empower data scientists to build robust, scalable, and efficient systems that drive business value. In this blog, we will explore the key engineering skills that every data scientist should master to excel in their career and make a tangible impact in the industry.
Writing a Clean Code:
As a data scientist, writing clean and maintainable code is crucial.

Below are my top 5 python packages that can help you achieve that. All of these are simple pip installation. They also have VS Code extension settings , if that is your IDE of preference.
📌 Black: It formats your python code for readability and uniformity.
📌 Pylint: It is a code analysis tool that checks for errors, enforces coding standards, and suggests improvements.
📌 flake8: It combines PyFlakes, and PEP8 to check the style and quality of Python code.
📌 isort: It automatically sorts Python imports, making them more consistent and readable.
📌 mypy: It is a static type checker for Python that helps in checking the type correctness of your code.
By integrating these tools into your development workflow, you can ensure your code is clean, consistent, and free of common errors.
Writing a Maintainable Code:
Imagine you are cooking a meal. Instead of doing everything at once, you break down the process into smaller tasks: chopping vegetables, cooking rice, grilling chicken, and making a sauce. Each task is a module, and it gets executed in a sequence, some of it you can parallelize like put the rice in cooker and chop vegetables. At the end, once all these small tasks are executed, your meal is ready. Also what if your sauce did not taste good, you can only focus on that task to fix it independently.
This is similar to modular programming, where we break down complex problems into smaller, manageable pieces, making it easier to debug, test, and understand. This is a powerful concept for data science projects.
If you are aware of MLOps , the major steps you follow in a project are: data collection, data pre-processing, feature engineering, model training, and model evaluation. Instead of writing one massive script, you can break these steps into separate modules. Lets take one as example:# dataset_ready.py : this is your module (.py) to prepare dataset with two functions for loading and preprocessing data.def load_data(file_path):
# code to load data
return data
def preprocess_data(data):
# code to clean and pre process data
return processed_data
This module can be called in your main as:
from dataset_ready import load_data, preprocess_data
data = load_data('yourdata.csv')
processed_data = preprocess_data(data)
You can have modules for other tasks from our MLOps as discussed earlier. Now you get the idea about how to decouple the code and organize it.
Version Control with Git:
Git is a powerful version control system that’s vital for managing code and collaborating in data science projects. Here are two most common scenarios demonstrating the top Git commands every data scientist should know:
Scenario 1: Cloning a New Repository and Making Changes:
# Step 1: Clone the repository
git clone https://lnkd.in/gpdYs73X
# Step 2: Create a new branch
git branch feature-data-cleaning
# Step 3: Switch to the new branch
git checkout feature-data-cleaning
Task for you: step 2 and 3 can happen at once. I leave it for you to figure out.
Or I shared it on scenario two. # Step 4: Make changes, add files, and commit
# (Assuming you added a data_cleaning_script.py file)
git add data_cleaning_script.py
git commit -m "Added data cleaning script"
# Step 5: Push changes to the remote repository
git push origin feature-data-cleaning
Scenario 2: Committing New Changes from a Feature Branch in an Already Cloned Repository:# Step 1: Navigate to the local repository
cd data-science-project
# Step 2: Pull the latest changes from the main branch. This is important to avoid merge conflicts.
git pull origin main
# Step 3: Create and switch to a new branch
git checkout -b feature-data-visualization
# Step 4: Make changes, add files, and commit
# (Assuming you added a visualization_script.py file)
git add visualization_script.py
git commit -m "Added data visualization script"
# Step 5: Push changes to the remote repository
git push origin feature-data-visualization
By mastering these Git commands and workflows, you’ll streamline your development process and enhance collaboration on data science projects. There are many other scenarios, but for simplicity I covered the most common ones for you to get started.
Don’t wait to learn about them. You better Git on It 😃
Mastering APIs:
Transitioning a data science project from notebook to a production environment is a critical skill for any data scientist. APIs and web services play a key role in this process, enabling seamless integration and deployment.
An API (Application Programming Interface) allows different software systems to communicate with each other. It exposes specific functionalities and data to other applications. It is like a waiter in restaurant who takes customer's order, sends it to kitchen, and serve the food once ready 🥗

REST APIs are the most common that use standard HTTP methods for interaction. You can use frameworks like Flask, FastAPI, or Django to build your API. These frameworks simplify the process of creating endpoints to serve your ML models.
Now you have the API, how would you deploy it? This is when docker comes for your rescue, helping you to containerize your application for deployment. Docker also assures the consistency across different environment and dependencies.
Mastering Containerization and Orchestration:
Containerization and orchestration are two essential skills for deploying scalable and reliable data science applications. Think of it like a cargo ship: containers are Docker containers, and the ship is the orchestrator (Kubernetes) to host the container.

Once your API/ web-service is ready to deploy, you need to package it along with its dependencies into a single entity - and it's called container. This ensures the consistency of your application across different environments. Docker is a tool to help us achieve that. Below are 3 simple steps:
📌 Create a dockerfile: it defines the environment and steps to run your application
📌 Build the image: docker build -t my-app .
📌 Run the container: docker run -p 4000:80 my-app
Now the container is ready, next task is to orchestrate it. Kubernetes is the most popular option. Below are 3 simple steps:
📌 Create the deployment config in a yaml file
📌 Deploy to Kubernetes: kubectl apply -f deployment.yaml
📌 Expose your deployment: another yaml file to create a service
Additionally, there will be monitoring and scaling options that you can set up in Kubernetes. By mastering these skills with Docker and Kubernetes, you can ensure your data science applications are robust, scalable, and easy to manage.
Structuring your Data Science Project:
I have come across many online resources about organizing data science project in git. Some of them are too extensive, and we may not need them all. Having too many baskets than eggs, is not a great idea.
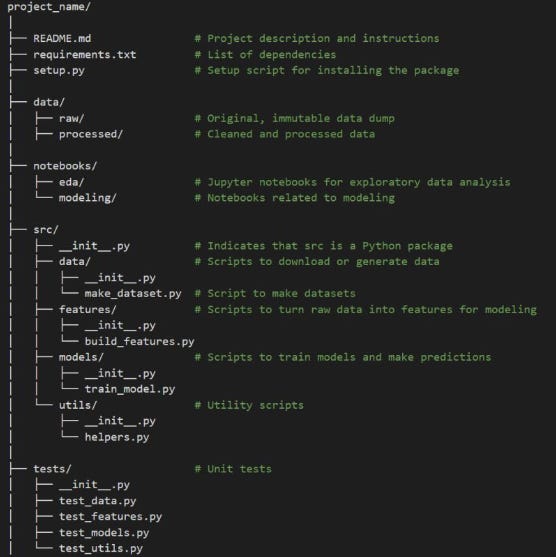
I am adding a simple, yet very effective way of organizing your data science project.
📁 README.md: a markdown file containing an overview of the project, installation instructions, usage, and other relevant information. This is important. Please don't have one liner readme.
📁 requirements.txt: list of dependencies required for the project.
📁 setup.py: if you have script to set up environment
📁 data: This folder contains all data-related files.
- raw: Original data that should not be modified.
- processed: Cleaned and processed data ready for analysis.
📁 notebooks: Jupyter notebooks categorized by their purpose.
- eda: Notebooks focused on exploratory data analysis.
- modeling: Notebooks used for building and evaluating models.
📁 src: source code for the project, organized into sub-modules.
- data: Scripts for downloading, generating, and processing data.
- features: Scripts for creating features from raw data.
- models: Scripts for training models and making predictions.
- utils: Utility scripts for various helper functions.
📁 tests: contains unit tests for the code in the src directory.
As long as you have your project organized as above, that should be more than sufficient.
If you find this blog valuable, please subscribe for more insightful blogs in data science and machine learning.