
Data Vs. Model Bias in Data Science
Are you understanding the difference and handling them properly?

Data Bias and Model Bias are two different things. Both of them can affect the performance of machine learning (ML) models. Before we jump into comparing these two biases, first let's try to understand- what is bias?
Bias refers to a conscious or unconscious preference towards certain things- it could be certain group of people or events, certain assumptions we make, certain choices we made or certain beliefs we have.
Data Bias occurs when the data used for training the model is not the representative samples of the actual population. In other words, the training data is not quite representing the real-world data.
Model Bias occurs when the model itself is not able to accurately represent the underlying relationship between the input features and the output variable. In other words, the model is too simple.

We have to understand the difference between these two biases, so we can mitigate each of them. For data bias, it's important to be aware of common human biases or the biases infused by data collection and sampling process. For model bias, it's important to choose a right model or algorithm, and tune its hyperparameters to get the optimal results.
Keep In Mind: The most popular discussion in machine learning regarding the bias vs. variance tradeoff, is mostly talking about the model bias.
Among these two biases, the first one to understand and tackle would be data bias, because it is already present in the data before we start modeling.
Example story of data bias: Back in 2015, Amazon realized that its AI enabled hiring tool was not rating candidates for software developer jobs in a gender-neutral way. Upon investigating, the researchers found that their model was trained to vet applicants by observing patterns in resumes submitted to the company over a 10-year period. Most of the applications were representing men, which shows a reflection of male dominance across the tech industry. In effect, the model believed that male candidates were preferable.
As we see in this example, one of the most common types of data bias happens when some variable occurs more frequently than others. Therefore, it is important to analyze the distribution and imbalance in data- not only from the target label’s perspective but also from input attributes.
One of the common mistakes we make while we are doing correlation analysis is that we are always seeking for input variables that are highly correlated to the target variable. The logic is true- In machine learning, we have learned that the input variables should be independent of each other, but the target variable should be dependent on input variables for high predictive power. However, we have to be very cautious if those input variables are sensitive features like gender, age, location etc.
I remember when I was working in Wells Fargo Bank, the model risk and governance team were not allowing us to use zip code as a feature for our loan approval model. The reason is to avoid data bias- as they have noticed some zip codes have more approved applications than others. This could potentially create data bias making model to believe applications coming from certain zip codes are preferable. When we looked into the data more carefully, we realized that the location feature was just a casual effect from the status of people living there- whether people with bad credit or people with good credit.
One more thing to keep in mind- when we impute missing values, we have to be aware if we are infusing biased data. For example, the mean imputation can often skew the distribution.
Some of the other examples of data bias are reporting bias, selection bias, automation bias, group attribution bias, and implicit bias. The most challenging one in my opinion is the implicit bias because we cannot control other’s belief or stereotype while collecting inputs from them.

Now let's come to the model bias. As we defined it earlier- model bias happens when we fail to find that optimal relationship between input features and output variable. The model error can be broken down as:
Model Error = Variance + Bias² + Noise
Bias represents the inherent error that we get from our model regardless of training data size. Our model is “biased” to a particular type of solution. For example, we are using simple linear classifier, when there exists non-linear relationship between the inputs and output.
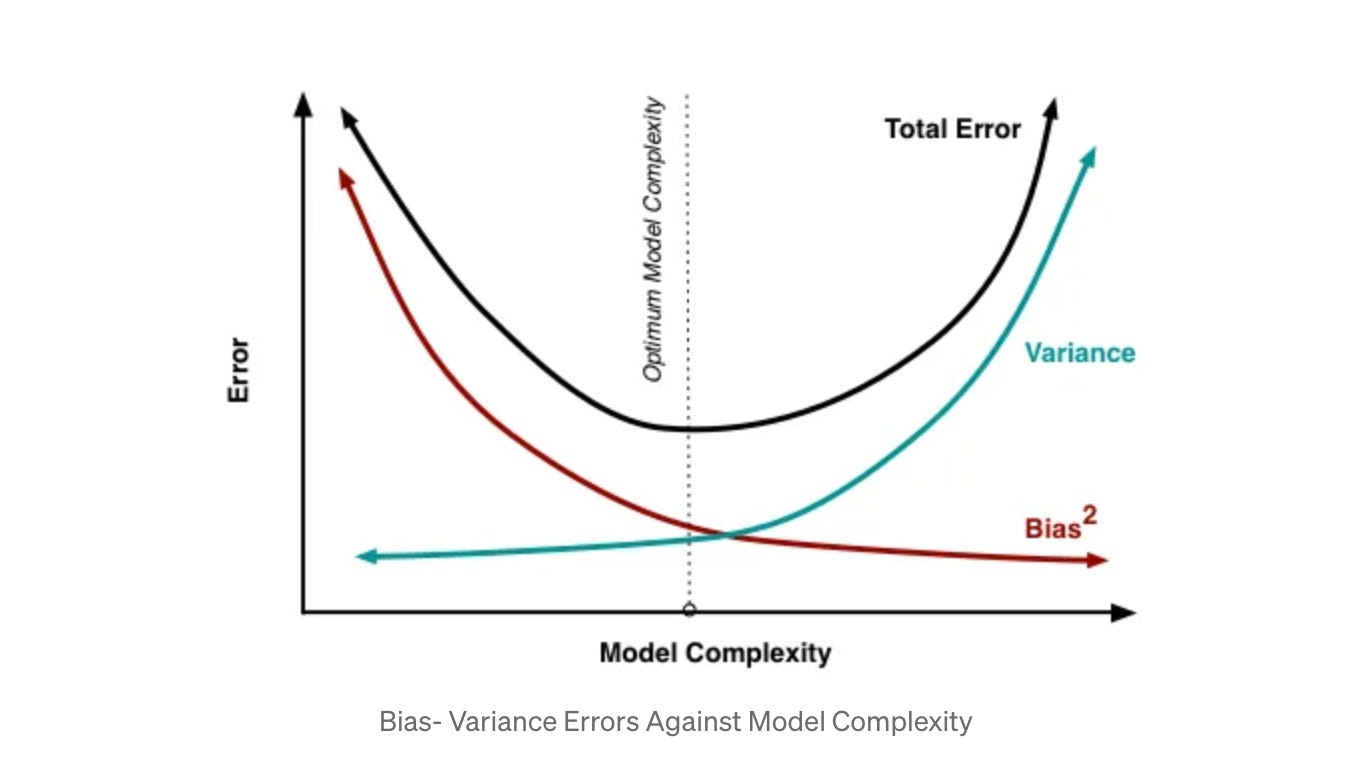
Model having a high bias is also referred to as under-fitting. It is diagnosed by looking and comparing the training and validation error. If both of them are lower than the acceptable error, then we have high bias in our model.
Some of the methods to overcome high bias are:
Use more complex model (e.g., kernelize, use non-linear models)
Add features: Remember it's about adding more features NOT more data. If variance is also high, then we can add data, but if variance is low with high bias, then adding data will not help much.
Boosting: combing weak learners to create a strong learner
In conclusion, data bias and model bias are different types of biases, both of which should be identified and mitigated. Data bias can lead our ML model to make biased decision because we trained it with biased data, however the model bias can lead our model to make inaccurate predictions because we are using simple model whose parameters are not enough to capture the underlying relationship of input features with desired output.